Please check this out. (Account TRU, Toys R Us).
Last time you had to reset the server
Hi,
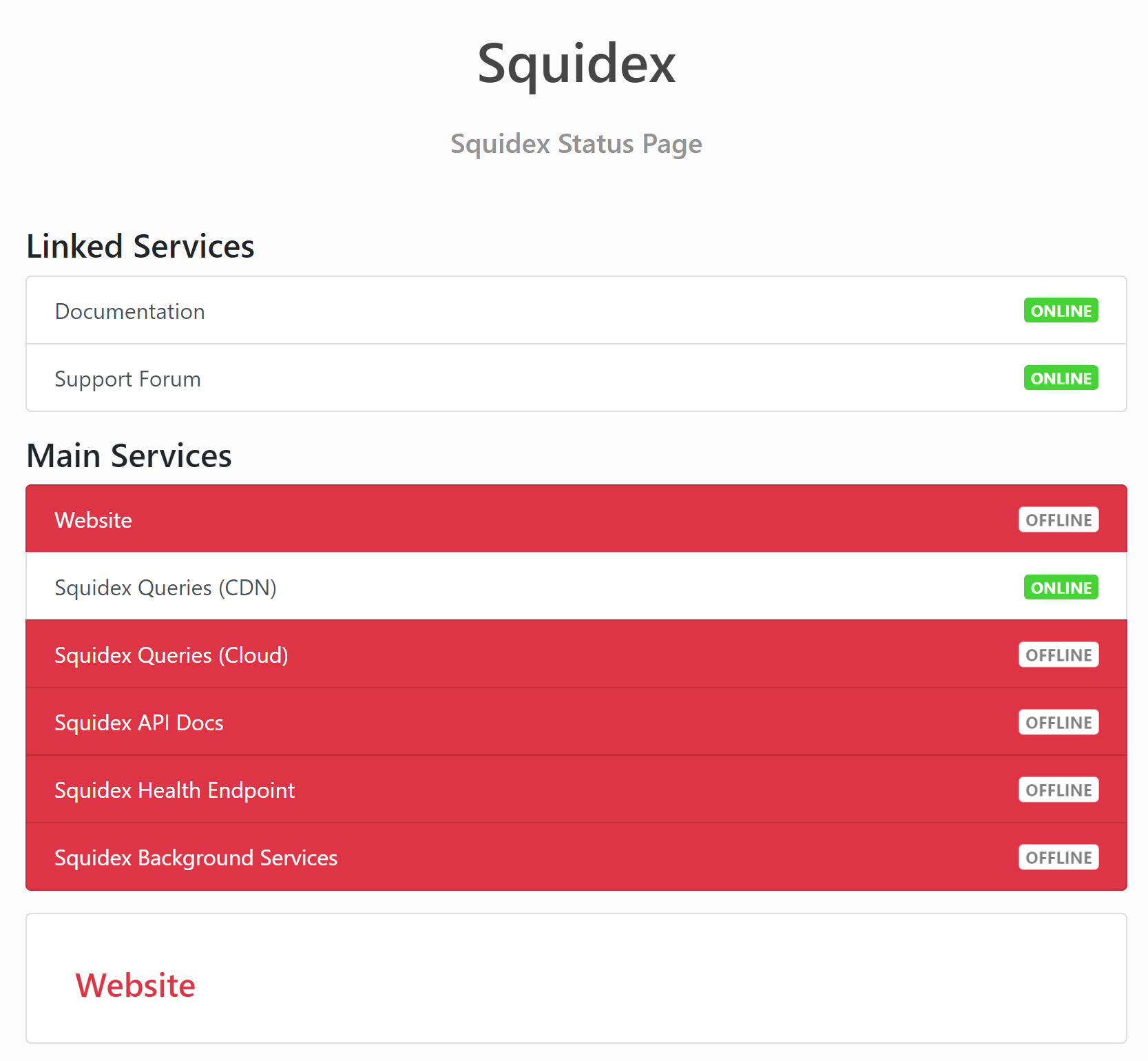
I am aware of that, but I have no idea what the problem is. The cloud is working fine for me and the website shows not a single error internally.
Okay, I was wrong. There is a Squidex website error. But it is a 503 from Cloudflare.
The most important thing right now is that the Israeli Toys R Us app doesn’t work. They have 0.5 millions active users. Please do something. (You had to reset the server last time)
This is not a problem anymore. The servers are stable. Do you use CDN?
No, and none of our users is able to access the app. They connected directly to Squidex
I have restarted the secondary database instances one by one.
and it fixed toys r us
Thanks, what did you have to do?
As I said: I restarted the secondary database servers. The content queries on for all clients except the dashboard go directly to the secondary servers to have just more performance available. Therefore the dashboard was not affected by this issue. It took me a while to figure this out. I don’t know yet, what caused the issue, because I had no time to analyze the load on the servers.
@Sebastian thank you for being available to sort this out for us. Your software is pretty stunning, keep up the good work. I am also backing an app with squidex and it has become super critical for our operation.
Thanks. I will see what I can do to improve this. Perhaps some health checks over the database. But it will be hard to find good metrics to do this automatically and you can easily screw up everything.
Maybe some sort of performance testing? My issue was super obvious. i get there can be a million different issues, but some application layer testing and threshold alerting might prevent an outcry. This is something I would like to implement with prometheus
I agree that it is a great product and thank you for the quick resolve, but this kind of problems happens every few months. It has to be solved
True, but it has different reasons. One big problem before 7.0 was the use of Orleans and that I was not able to provide a stable setup for it. With Orleans you have a cluster of connected API servers that work together, but when the majority of servers goes down the cluster is not stable anymore. This problem is now solved with 7.0 and so far it looks very good. Squidex just does not use Orleans anymore.
The issue with the database is a complete other reason but part of the problem are noisy neighbor effects that can only be partially solved. With the dynamic nature of Squidex content it is impossible to optimize every database call and one user can theoretically bring other users down. I think this is what happened here somehow. If you know what kind of queries you can make, you can optimize the database calls, create indexes and so on. This is not possible here. But I have found a bug that was prevent timeouts to work properly. If we enforce harder limits on the kind of queries that can be made, it is less likely that it happens.
But it is also related to the pricing model. With 19€ or 49€ or even 99€ a month it is impossible to provide a dedicated installation with your own database and own API servers. This would be more in the price range of contentful (but I am not sure if they provide dedicated servers).
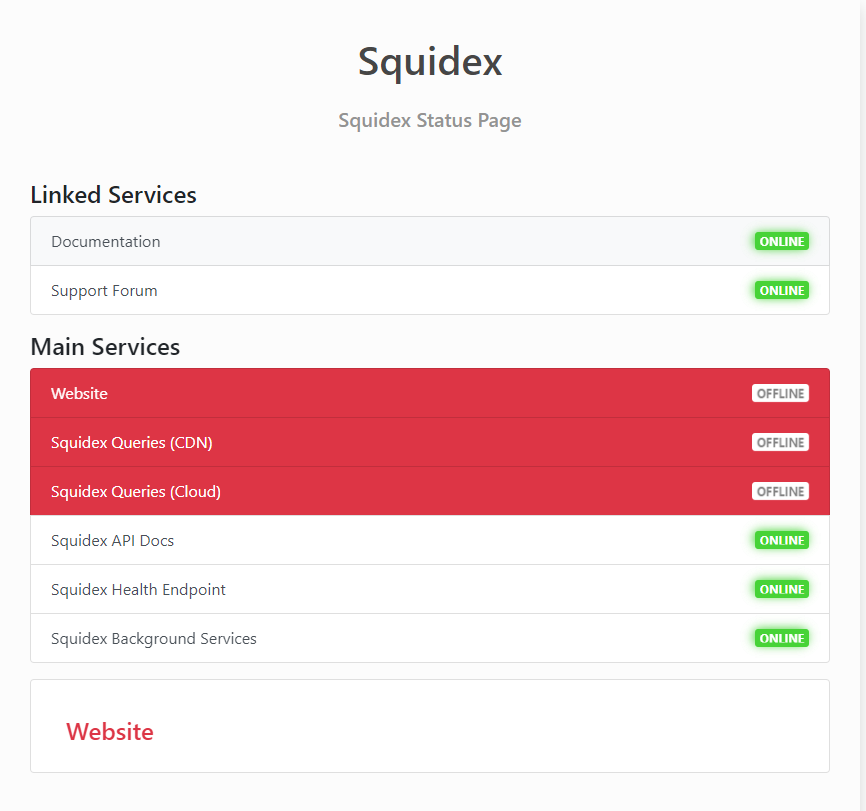
@Sebastian once again same problem. Please resolve the problem ASAP!! our client wants us to leave squidex because of so many failures. Squidex.io is also down
I have already reported the issue in another thread.