I have…
I’m submitting a…
- [ ] Regression (a behavior that stopped working in a new release)
- [ ] Bug report
- [ ] Performance issue
- [ ] Documentation issue or request
Current behavior
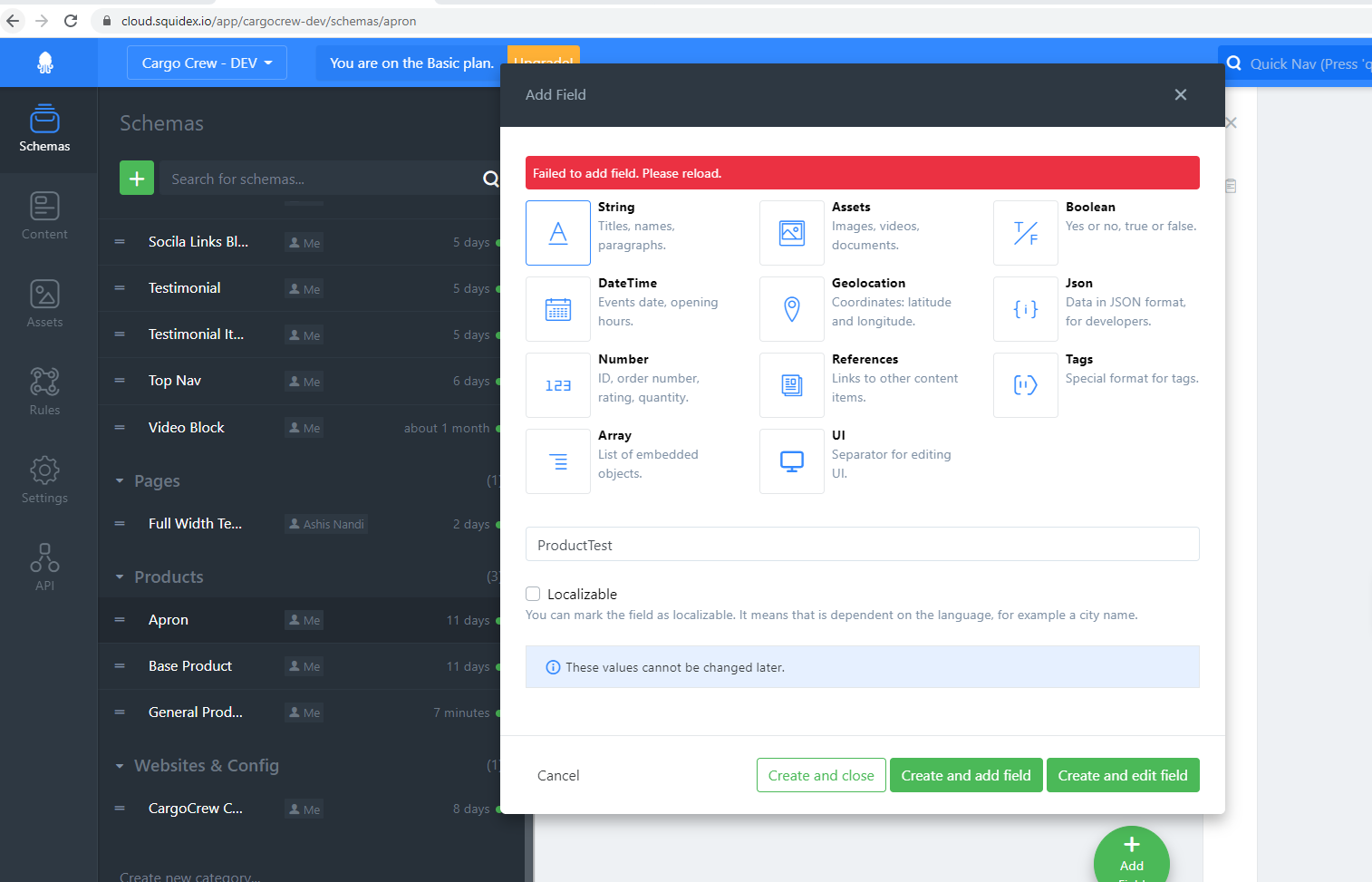
We are not able to modify schema by adding/updating fields.
We are getting the below error.
Can you please help out to resolve this.
Thank you.
Expected behavior
Minimal reproduction of the problem
Environment
- [ ] Self hosted with docker
- [ ] Self hosted with IIS
- [ ] Self hosted with other version
- [ ] Cloud version
Version: [VERSION]
Browser:
- [ ] Chrome (desktop)
- [ ] Chrome (Android)
- [ ] Chrome (iOS)
- [ ] Firefox
- [ ] Safari (desktop)
- [ ] Safari (iOS)
- [ ] IE
- [ ] Edge
Others:
Please provide all the information from the checkboxes.
This issue is appearing only if I click on “Create and close”. “Create and add field” is working.
Okay, good to know. I will have a look.
I just added the field to your schema and it works for me.
I think I found the issue and will provide a fix tomorrow.
For developers
The problem is the following code as an example:
public class MyTest
{
public DomainId Calculated
{
get { return DomainId.Combine(Id0, Id1.Id); }
}
public DomainId Id0 { get; set; }
public NamedId<DomainId> Id1 { get; set; }
}
This code can potentially throw an exception in the property Calculated, when Id0 is null. Usually it does not happen. When the property is the first property the serializer tries to deserialize them in order.
When JSON.NET deserializes a property it also ready the property. I guess to support deserializing to readonly collection properties. But when the calculated property is the first Id1 is null at this moment and a NullReferenceException is thrown. There are 2 potential fixes:
- Making the calculated property the last property, which is not possible when
Id1 is defined in a base class.
- Ignoring the calculated property during serialization, which is the correct fix in my opinion anyway, because it safes a few bytes and improves performance.
Sometimes, when a request is received at NodeA, it needs to be forwarded to NodeB and this is when the serialization problem happens. So it is actually totally random.
1 Like