Was looking for some clarification on best practices for implementing components vs schemas. Take the ERD example below.

In this example I have two definite schemas. First, the homepage which is a single content schema because I want to allow the editor to edit the content on the homepage. Second, is the Link, because I want this piece to be shared for SEO purposes. This way links with the same name will always have to point to the same url. It also allows me to add inline editing for the editor role on the list since there will likely be multiple names for the same href tag.
What I’m trying to decide is the best practice for the next three pieces shown in gray.
First we have the ProductCategorySection which is an array in the homepage. ProductCategorySection of course will have Products (or in this case ProductCarouselItem), and a product item will have a UniversalImage (which is a simple definition of image and string today for simplicity of the question, but will likely have more fields)
What I’m trying to understand better here in this example is what makes the most sense from a squidex implementation?
Should components inherit other components? Should most things be a schema? etc… What makes the most sense from just a performance standpoint outside of having a reusable component thats part of a schema and not directly editable?
To give you a further example, taking the example above I could set up the following…
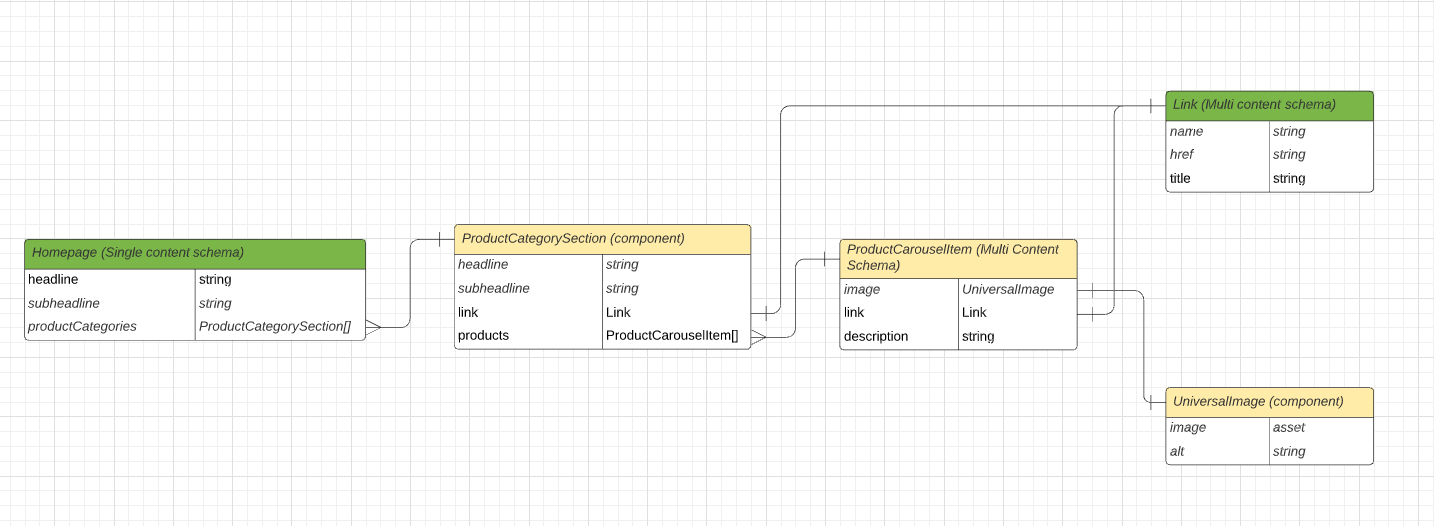
Basically in this case universal image is a component because its uniqueness does not matter and a general editor is not important. ProductCarouselItem inherits this as a field and it is a multi-content schema because it will get used in multiple pieces and being able to share it across schemas would be useful. ProductCategorySection relates directly to a page and is not shared, so it could be a component.
Anyways, I know this is a new feature, and I just thought it would be helpful to get some clarification on how you saw components vs schema usage so we can take the right steps for long term implementation.
Also, side note, as this is my first support ticket, I just wanted to thank you for building Squidex. We actually tried an implementation of Strapi before Squidex, and going to Squidex has been like finding water in a desert. The difference in code standards, UI, performance and just in general ability to search past support issues in the forum is significantly better. I really appreciate the time and effort you’ve put into this project.