With discourse action I also refactored the rule system. Before it followed a layered architecture, but you had to make dozens of changes in different files.
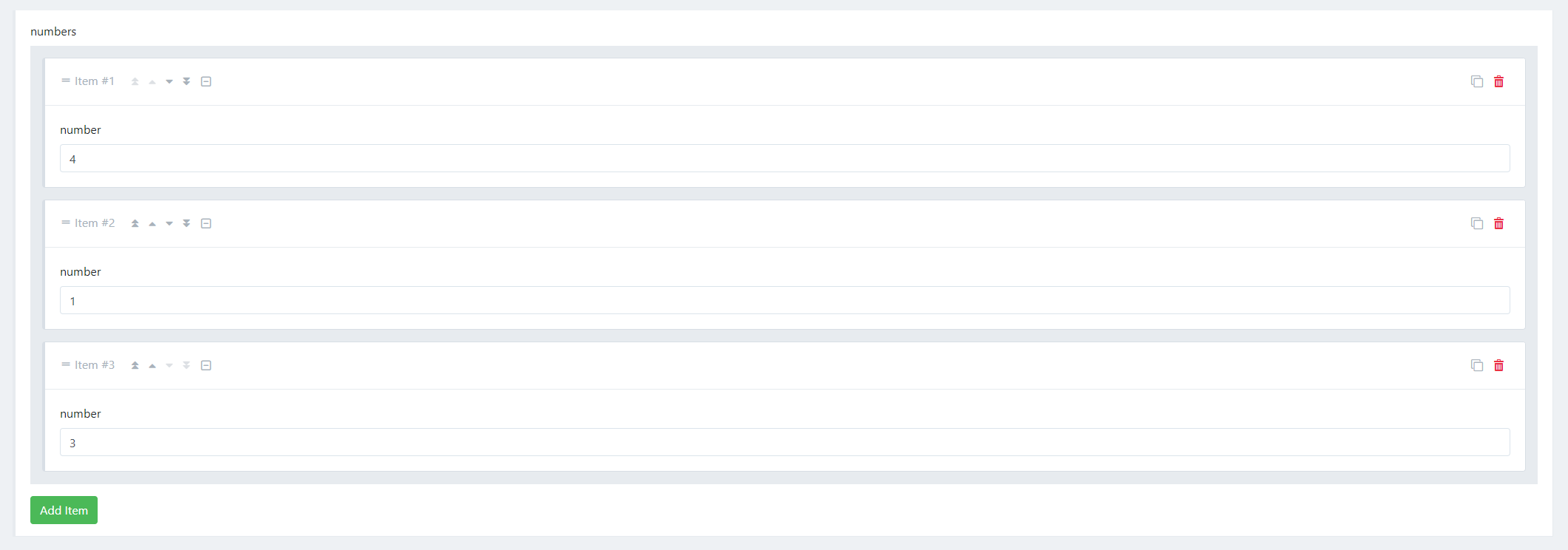
It is much easier now because you only have to create 5 files to create a new rule action now and hopefully only 2 when we can autogenerate the UI for an action in a later release. It is about 150 lines of C# code which is very good I would say.
it is also the first step to a plugin system, where we have to sharpen our interfaces.
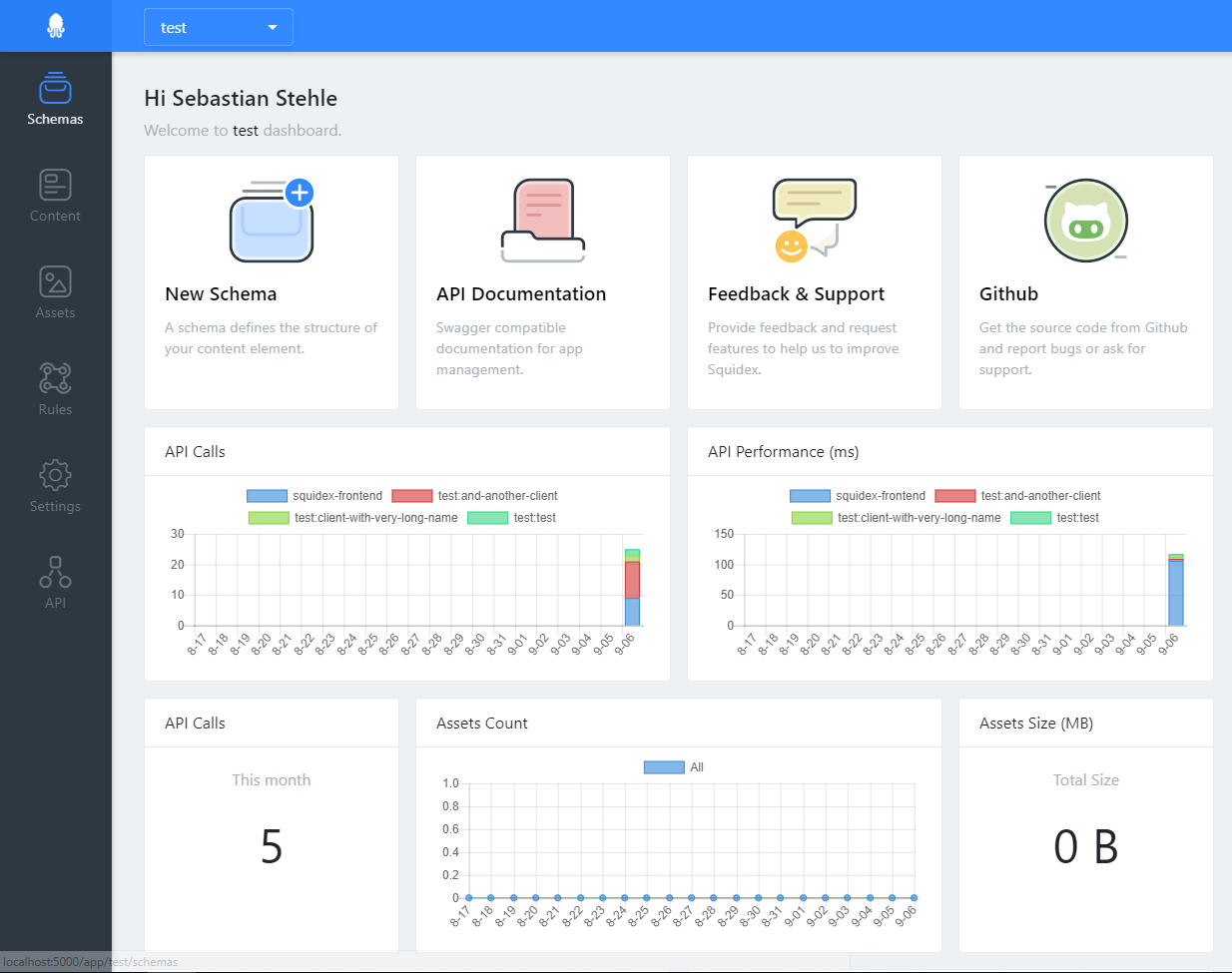
The feature was requested by a user who had a bug in his client and consumed almost all his API calls within a few days and it was hard for him to find out what happened with all the API calls.
I deployed a new version with a lot of performance improvements in the UI. I spent several days to test it but I assume that it will not be bug free. Sorry for the inconveniences.
I think the image speaks for itself. I know that there are more important things in our roadmap, but this was straight forward to implement, so I thought I can have some fun and implement something useful.
I have deployed it. I also made some changes and improvements to the Etag support and also added support to the Management UI. It will make the same requests, but it will retrieve a 304 very often now and handle this properly.
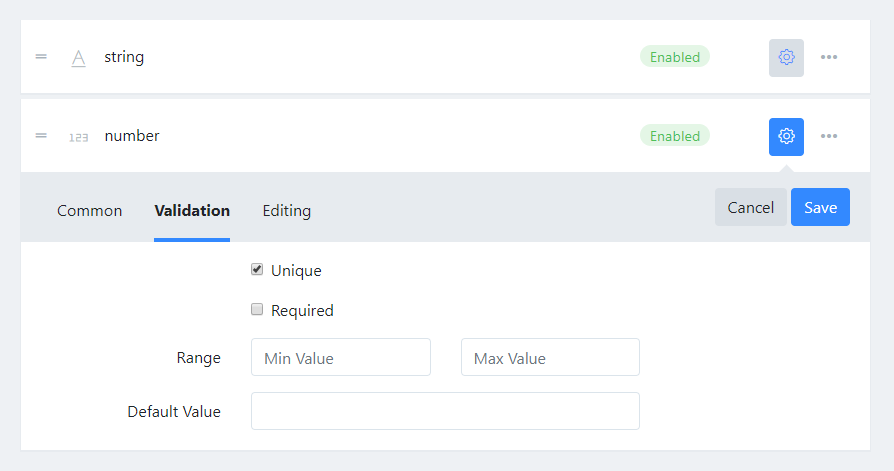
I have added uniqueness validation for string and number fields.
There are some restrictions:
It only works for non-localized fields.
It does not work for nested fields.
The reason is that squidex has to make a database call per unique field for each update. Without the restriction it could end up in hundreds of calls per updated.
It is only a validation check, e.g. if two users create a content item at the same time you could still get duplicates but this is not a very likely event in the context of a headless CMS. A check on the database level would increase the consistency but would also create hundreds of indices and hurt the performance too much.
For now it only contains the feature to export content to JSON or CSV, but more features will come or when they are requested.
The CLI will provide an integrated help but here are some hints how to use it. The examples are for windows but I also published the binaries for OSX and Linux:
// Add an app to the configuration file
sq.exe config add squidex-website CLIENT_ID CLIENT_SECRET
// Show all apps
sq.exe config view
// Remove an app
sq.exe config remove squidex-website
// Switch to another app
sq.exe config use-app other-app
// Export schema to a single JSON
sq.exe content export blog
// Export schema with one file per content.
sq.exe content export blog -m
// Export schema to CSV
sq.exe content export blog -fields Id,Date=Created,Slug=data.title.iv,Text (English)=data.text.en
Why a CLI?
It takes so much time to write a good UI for it
it is easier to integrate a CLI in automated processes, such as nightly backups
Why is it so big?
It is a restriction of .NET Core and unfortunately there is no easy way to create a single file. I could write it in GO, but I would need much more time.