This is the first feature description of a new content item. I would like to present the concept here to get some feedback before it will be implemented.
Previous Workflow System
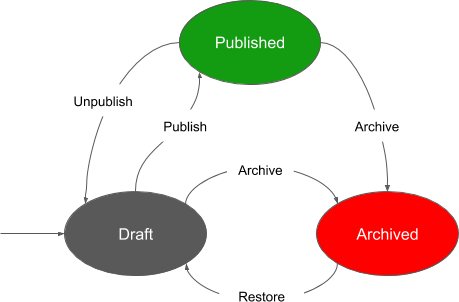
When we started with Squidex there was a very simple workflow system. Basically a content was in one these statuses:
- Draft: The default state indicating that somebody is working on the content but it is not ready yet.
- Archived: Soft deletion for content items. Content you don’t need anymore but you don’t want to delete it either. There was a very small button in the UI to see the archived content items as well.
- Published: For content items that are ready and is available in the API.
As a diagram it was looking like this:
Then we had a very great feature request: Someone said that they would like to work on published content and save it but not publish the new version immediately. Therefore we introduced a new feature, where you can edit a published content item and save it as draft. You can either publish this draft then or discard it to delete it. This is like a mini-workflow for published content items.
So we got a new workflow that looks basically like this:
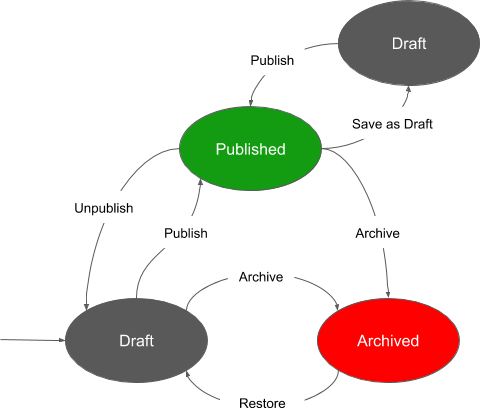
Each content item has now two data objects which holds the values of the fields.
- DataDraft: The content that you are currently working on. This can either be the normal content or a copy of the content when you have already published the content item before. This content is shown in Management UI and also used for filtering and searching.
- Data: The last published content or the normal content if you have never published the content item before. This content is used in the public API.
By default you only get the Data object in the public API, because you only get published content items there, but you can also request all content items. Then you will see both objects.
What is the problem?
There are a few problems with this approach.
Custom workflows
Last year we introduced custom workflows. This feature makes it possible to adjust the workflows to your needs, for example you can introduce multiple review stages.
If you also do not need the archived state it might look similar to this:
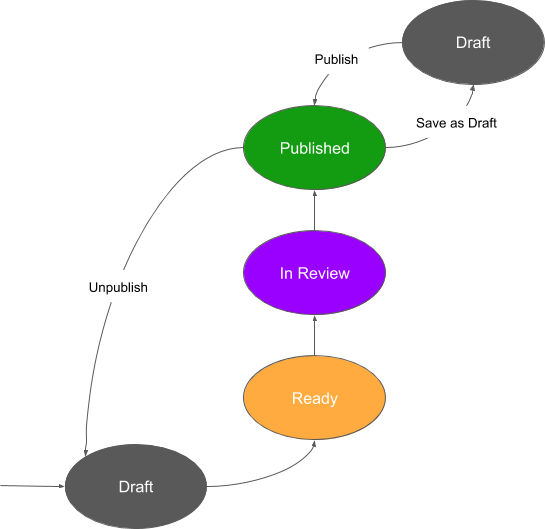
As you can see the mini-workflow stays the same. This means, that once your content item is published you can basically bypass all review stages. You can prevent this with permissions but this is not the optimal.
Technical issues.
To serve both data objects we store them in a single document in the database. This means that the content record in the database is twice as big as it needs to. This adds an unnecessary overhead to the database. Furthermore MongoDB has several limitations around document size and memory usage that can be problematic.
More about this in the following article: https://docs.mongodb.com/manual/reference/limits/#Sort-Operations
The new concept
The overcome this problem we have found the following solution. We still need to find a good name for it, but for now we call it content versions. The term “version” is used very often in Squidex already, so I would like to find a better and unique term for it.
The idea is to create new versions of your content item.
I think the best is to show a mockup first:
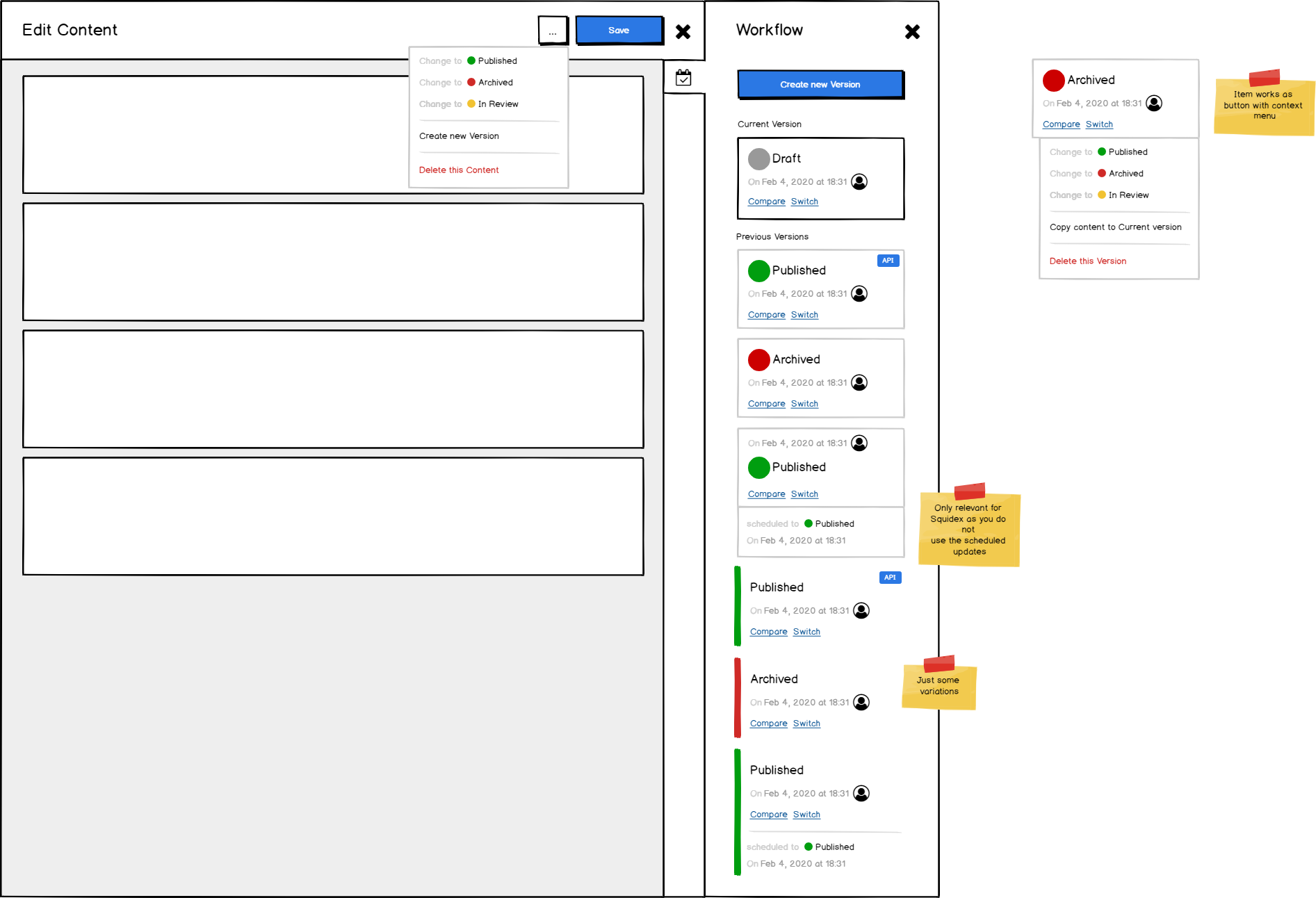
In short it works like this:
- Each content item can have multiple versions.
- Versions are independent, each of them has a status and will workflow the workflow steps with all restrictions and rules that might be configured for the workflow.
- Versions can be scheduled to a new status independently.
- Versions can be deleted and new permissions will be introduced to decide who can create or delete a version.
- The status of the content item that is also used for filtering is the same like the status of the last version.
- The management UI will show and use the data object of the newest version.
- The public UI will show and use the data object of the newest published version.
- The content item can have multiple versions that are in published state. This might be irritating when you consume the content via the API but other users use kafka or other messaging systems to consume the content and for them published very often means that it has been pushed to a messaging system.
On the technical side we will get two collections in MongoDB for content items. One collection will contain the data object of the last version and will be used for the Management API or if you want to get all content items, even if they are not published. The other collection will only contain published items.
This means that it will not be possible to get both, the last published data object and the last data object, for a content item.